functioninstance_of(V, F){ var O = F.prototype; V = V.__proto__; while (true) { if (V === null) returnfalse; if (O === V) returntrue; V = V.__proto__; } }
// ECMA-262, section 11.8.6, page 54. To make the implementation more // efficient, the return value should be zero if the 'this' is an // instance of F, and non-zero if not. This makes it possible to avoid // an expensive ToBoolean conversion in the generated code. functionINSTANCE_OF(F){ var V = this; if (!IS_SPEC_FUNCTION(F)) { throw %MakeTypeError('instanceof_function_expected', [F]); }
// If V is not an object, return false. if (!IS_SPEC_OBJECT(V)) { return1; }
// Check if function is bound, if so, get [[BoundFunction]] from it // and use that instead of F. var bindings = %BoundFunctionGetBindings(F); if (bindings) { F = bindings[kBoundFunctionIndex]; // Always a non-bound function. } // Get the prototype of F; if it is not an object, throw an error. var O = F.prototype; if (!IS_SPEC_OBJECT(O)) { throw %MakeTypeError('instanceof_nonobject_proto', [O]); }
// Return whether or not O is in the prototype chain of V. return %IsInPrototypeChain(O, V) ? 0 : 1; }
这两个的区别在JavaScript’s typeof operator中有说到:You can always swap {} with Object.prototype, to save creating an object just to exploit its toString() method.。也就是使用Object.prototype.toString会节省创建一个对象。
// ECMA-262, section 9.1, page 30. Use null/undefined for no hint, // (1) for number hint, and (2) for string hint. functionToPrimitive(x, hint){ // Fast case check. // 如果为字符串,则直接返回 if (IS_STRING(x)) return x; // Normal behavior. if (!IS_SPEC_OBJECT(x)) return x; if (IS_SYMBOL_WRAPPER(x)) throw MakeTypeError('symbol_to_primitive', []); if (hint == NO_HINT) hint = (IS_DATE(x)) ? STRING_HINT : NUMBER_HINT; return (hint == NUMBER_HINT) ? %DefaultNumber(x) : %DefaultString(x); }
// ECMA-262, section 8.6.2.6, page 28. functionDefaultNumber(x){ if (!IS_SYMBOL_WRAPPER(x)) { // 转换为数字原始类型时,首先通过valueOf来转换 var valueOf = x.valueOf; if (IS_SPEC_FUNCTION(valueOf)) { var v = %_CallFunction(x, valueOf); if (%IsPrimitive(v)) return v; }
// 否则通过toString var toString = x.toString; if (IS_SPEC_FUNCTION(toString)) { var s = %_CallFunction(x, toString); if (%IsPrimitive(s)) return s; } } // 否则抛出异常 throw %MakeTypeError('cannot_convert_to_primitive', []); }
// ECMA-262, section 8.6.2.6, page 28. functionDefaultString(x){ if (!IS_SYMBOL_WRAPPER(x)) { // 转换为字符串原始类型时首先通过toString var toString = x.toString; if (IS_SPEC_FUNCTION(toString)) { var s = %_CallFunction(x, toString); if (%IsPrimitive(s)) return s; }
// 否则通过valueOf var valueOf = x.valueOf; if (IS_SPEC_FUNCTION(valueOf)) { var v = %_CallFunction(x, valueOf); if (%IsPrimitive(v)) return v; } } // 否则抛出异常 throw %MakeTypeError('cannot_convert_to_primitive', []); }
ToNumber
ToNumber是用于将变量转换为number类型,它在V8中的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// ECMA-262, section 9.3, page 31. functionToNumber(x){ // 如果为number直接返回 if (IS_NUMBER(x)) return x; // 如果为字符串,则调用StringToNumber转换 if (IS_STRING(x)) { return %_HasCachedArrayIndex(x) ? %_GetCachedArrayIndex(x) : %StringToNumber(x); } if (IS_BOOLEAN(x)) return x ? 1 : 0; // 如果为undefined,则返回NAN if (IS_UNDEFINED(x)) return NAN; // 如果为symbol,则抛出异常 if (IS_SYMBOL(x)) throw MakeTypeError('symbol_to_number', []); // 如果为null或 return (IS_NULL(x)) ? 0 : ToNumber(%DefaultNumber(x)); }
ToString
ToString是用于将变量转换为string类型,它在V8中的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
// ECMA-262, section 9.8, page 35. functionToString(x){ // 如果为string,则直接返回 if (IS_STRING(x)) return x; // 如果为number,则调用_NumberToString if (IS_NUMBER(x)) return %_NumberToString(x); // 如果为boolean if (IS_BOOLEAN(x)) return x ? 'true' : 'false'; // 如果为undefined,则返回undefined字符串 if (IS_UNDEFINED(x)) return'undefined'; // 如果为symbol,则抛出异常 if (IS_SYMBOL(x)) throw %MakeTypeError('symbol_to_string', []); // 如果为null,或者对象 return (IS_NULL(x)) ? 'null' : %ToString(%DefaultString(x)); }
// ECMA-262, section 11.6.1, page 50. functionADD(x){ // Fast case: Check for number operands and do the addition. // 如果都为number或string,则直接调用NumberAdd或_StringAdd if (IS_NUMBER(this) && IS_NUMBER(x)) return %NumberAdd(this, x); if (IS_STRING(this) && IS_STRING(x)) return %_StringAdd(this, x);
// Default implementation. // 否则将两边操作数分别转换为原始类型 var a = %ToPrimitive(this, NO_HINT); var b = %ToPrimitive(x, NO_HINT);
// ECMA-262 Section 11.9.3. functionEQUALS(y){ if (IS_STRING(this) && IS_STRING(y)) return %StringEquals(this, y); var x = this;
while (true) { // 如果x为number if (IS_NUMBER(x)) { while (true) { if (IS_NUMBER(y)) return %NumberEquals(x, y); if (IS_NULL_OR_UNDEFINED(y)) return1; // not equal if (IS_SYMBOL(y)) return1; // not equal if (!IS_SPEC_OBJECT(y)) { // String or boolean. return %NumberEquals(x, %ToNumber(y)); } y = %ToPrimitive(y, NO_HINT); } } elseif (IS_STRING(x)) { while (true) { if (IS_STRING(y)) return %StringEquals(x, y); if (IS_SYMBOL(y)) return1; // not equal if (IS_NUMBER(y)) return %NumberEquals(%ToNumber(x), y); if (IS_BOOLEAN(y)) return %NumberEquals(%ToNumber(x), %ToNumber(y)); if (IS_NULL_OR_UNDEFINED(y)) return1; // not equal y = %ToPrimitive(y, NO_HINT); } } elseif (IS_SYMBOL(x)) { if (IS_SYMBOL(y)) return %_ObjectEquals(x, y) ? 0 : 1; return1; // not equal } elseif (IS_BOOLEAN(x)) { if (IS_BOOLEAN(y)) return %_ObjectEquals(x, y) ? 0 : 1; if (IS_NULL_OR_UNDEFINED(y)) return1; if (IS_NUMBER(y)) return %NumberEquals(%ToNumber(x), y); if (IS_STRING(y)) return %NumberEquals(%ToNumber(x), %ToNumber(y)); if (IS_SYMBOL(y)) return1; // not equal // y is object. x = %ToNumber(x); y = %ToPrimitive(y, NO_HINT); } elseif (IS_NULL_OR_UNDEFINED(x)) { return IS_NULL_OR_UNDEFINED(y) ? 0 : 1; } else { // x is an object. if (IS_SPEC_OBJECT(y)) { return %_ObjectEquals(x, y) ? 0 : 1; } if (IS_NULL_OR_UNDEFINED(y)) return1; // not equal if (IS_SYMBOL(y)) return1; // not equal if (IS_BOOLEAN(y)) y = %ToNumber(y); x = %ToPrimitive(x, NO_HINT); } } }
// ECMA-262, section 11.8.5, page 53. The 'ncr' parameter is used as // the result when either (or both) the operands are NaN. functionCOMPARE(x, ncr){ var left; var right; // Fast cases for string, numbers and undefined compares. if (IS_STRING(this)) { if (IS_STRING(x)) return %_StringCompare(this, x); if (IS_UNDEFINED(x)) return ncr; left = this; } elseif (IS_NUMBER(this)) { if (IS_NUMBER(x)) return %NumberCompare(this, x, ncr); if (IS_UNDEFINED(x)) return ncr; left = this; } elseif (IS_UNDEFINED(this)) { if (!IS_UNDEFINED(x)) { %ToPrimitive(x, NUMBER_HINT); } return ncr; } elseif (IS_UNDEFINED(x)) { %ToPrimitive(this, NUMBER_HINT); return ncr; } else { left = %ToPrimitive(this, NUMBER_HINT); }
right = %ToPrimitive(x, NUMBER_HINT); if (IS_STRING(left) && IS_STRING(right)) { return %_StringCompare(left, right); } else { var left_number = %ToNumber(left); var right_number = %ToNumber(right); if (NUMBER_IS_NAN(left_number) || NUMBER_IS_NAN(right_number)) return ncr; return %NumberCompare(left_number, right_number, ncr); } }
functiontopsort(edges){ var nodes = {}; var result = []; var queue = [];
// build data structres edges.forEach(function(edge){ var fromEdge = edge[0]; var fromStr = fromEdge.toString(); var fromNode;
if (!(fromNode = nodes[fromStr])) { fromNode = nodes[fromStr] = new EdgeNode(fromEdge); }
edge.forEach(function(toEdge){ // since from and to are in same array, we'll always see from again, so make sure we skip it.. if (toEdge == fromEdge) { return; }
var toEdgeStr = toEdge.toString();
if (!nodes[toEdgeStr]) { nodes[toEdgeStr] = new EdgeNode(toEdge); } nodes[toEdgeStr].indegree++; fromNode.afters.push(toEdge); }); });
// topsort var keys = Object.keys(nodes); keys.forEach(function(key){ if (nodes[key].indegree === 0) { queue.push(key); } }); while (queue.length !== 0) { let vertex = queue.shift(); result.push(nodes[vertex].id);
nodes[vertex].afters.forEach(function(after){ var afterStr = after.toString();
nodes[afterStr].indegree--; if (nodes[afterStr].indegree === 0) { queue.push(afterStr); } }); }
// build max heap for (let i = Math.floor(len / 2); i >= 0; i--) { precDown(arr, i, len) } // delete max element for (let i = len - 1; i > 0; i--) { swap(arr, 0, i); precDown(arr, 0, i); } return arr; }
functionswap(arr, i, j){ var tmp = arr[i]; arr[i] = arr[j]; arr[j] = tmp; }
functionmedian3(arr, left, right){ var center = Math.floor((left + right) / 2);
if (arr[left] > arr[center]) { swap(arr, left, center); } if (arr[left] > arr[right]) { swap(arr, left, right); } if (arr[center] > arr[right]) { swap(arr, center, right); }
swap(arr, center, right - 1); return arr[right - 1]; }
functionqSort(arr, left, right){ // 枢纽元 var pivot = median3(arr, left, right); var i = left; var j = right - 1;
while (i < j) { while (arr[++i] < pivot) {} while (arr[--j] > pivot) {} if (i < j) { swap(arr, i, j); } else { break; } } swap(arr, i, right - 1); if (left < i - 1) { qSort(arr, left, i - 1); } if (i + 1 < right) { qSort(arr, i + 1, right); }
let person = { getGreeting() { return"Hello"; } };
let dog = { getGreeting() { return"Woof"; } };
// prototype is person let friend = Object.create(person); console.log(friend.getGreeting()); // "Hello" console.log(Object.getPrototypeOf(friend) === person); // true
// set prototype to dog Object.setPrototypeOf(friend, dog); console.log(friend.getGreeting()); // "Woof" console.log(Object.getPrototypeOf(friend) === dog); // true
let person = { getGreeting() { return"Hello"; } };
let dog = { getGreeting() { return"Woof"; } };
// prototype is person let friend = { __proto__: person, getGreeting() { // same as this.__proto__.getGreeting.call(this) returnObject.getPrototypeOf(this).getGreeting.call(this) + ", hi!"; } };
// Syntax error: Can't have a named parameter after rest parameters functionsum(first, ...numbers, last){ let result = first, i = 0, len = numbers.length;
functionPerson(name){ if (typeofnew.target !== "undefined") { this.name = name; // using new } else { thrownewError("You must use new with Person.") } }
var person = new Person("Nicholas"); var notAPerson = Person.call(person, "Michael"); // error!
- (BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary *)launchOptions { // Override point for customization after application launch. // Add the view controller's view to the window and display. [window addSubview:viewController.view]; [window makeKeyAndVisible]; return YES; }
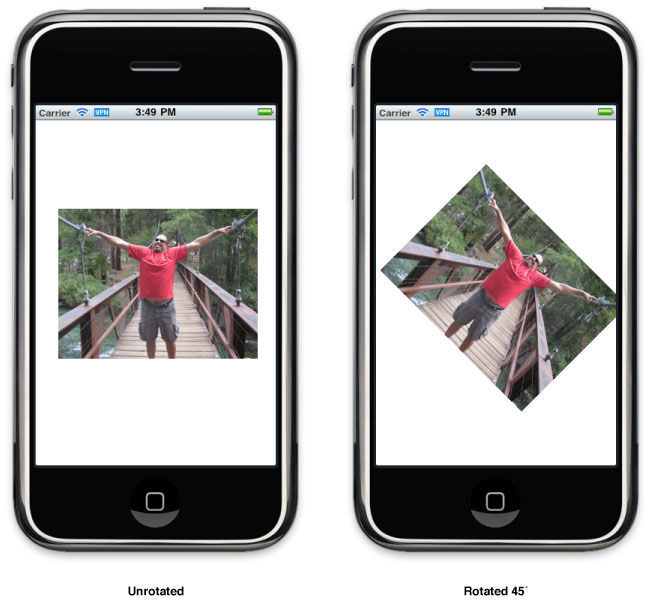
// M_PI/4.0 is one quarter of a half circle, or 45 degrees. CGAffineTransform xform = CGAffineTransformMakeRotation(M_PI/4.0); self.view.transform = xform;